What is a Mapping Constraint in DBMS?
In DBMS, Mapping Constraints are used to restrict the mappings between the entities in the schema. These constraints define how entities are linked through an Entity-Relationship (ER) model, giving a clear framework for implementing the associations. For example, they define whether an item in one set might be associated with one or more items in another set.
Entity-Relationship (ER) model
In the Entity-Relationship (ER) model, relationships show how different entities interact. They’re represented by a diamond-shaped box in the diagram, which connects the entities in the sample. For example, when a customer buys a product, the customer and the product are entities, and the purchase itself forms the relationship.
These relationships can also have attributes, like a timestamp that records when the purchase occurs. In this way, relationships can have unique characteristics that provide more detail about how entities interact. In this case, the relationship between the customer and products is “Buys”. Since there’s an associated timestamp, the “time” becomes an attribute of “buys”.
The concepts from sets and relations are extensively used to understand these database concepts. Going by the set theory, the above interaction can be represented as:
From the representation above the following can be inferred:
- Many customers can buy the same type of product.
- Many products can be purchased by multiple customers.
- Some products may never be bought by any customer.
- Some customers may not purchase any product at all.
Cardinality Ratios
Cardinality Ratios describe the extent of participation that an entity could have in other relationships. These constraints fall into four primary categories: The key linking mechanisms are:
- one-to-one
- one-to-many
- Many-to-one
- many-to-many
All kinds of mapping constraints contribute to defining the clear rules of associating the entities and guaranteeing that the connections between them are accurately defined.
When it comes to binary relationships, mapping constraints are more important as there are two entities connected. These assist the database designer in keeping the integrity and clarity of relationships that define the structure of a database.
Types of Mapping Constraints in DBMS
There are mainly four types of mapping constraints:
One to One Cardinality
The mapping constraint identified as One-to-One Cardinality occurs when one entity instance of one set is related to one entity instance of another set within the same entity-relationship model. This constraint is self-explanatory from its name; in fact, it only permits one-to-one entity mapping.
In this type of constraint, one particular entity instance in the set can only be related to another in the set no greater than once. Other cardinality types are used if multiple instances of the related entity must be mapped.
For example, think of the entities Employee and Salary Account. Among these entities, we have a relationship connecting them as “salary”. The industry rule of one-to-one cardinality means that every employee in a company will only be associated with one single salary account. There will be no exception to this rule relative to the employees in the organisation, and across the board, it will be strictly implemented. Thus, it is one-to-one and relates the employee entity to the salary account entity.
One to Many Cardinality
The One-to-Many Cardinality applies when one single entity instance from one set within the same ER model needs to be related to more than one entity instance from another set. As the name implies, it reflects its true function of enabling one-to-many associations.
In this type of constraint, one entity instance in the left set is related to many entity instances in the right set. If the relationship requires the use of more than one entity on the left side or a single entity on the right side, there are other kinds of cardinality to be used.
For example, the specification may contain the following entities: Employee and Sales connected by the relation Job. In this case, one employee in a company can produce several sales. However, the cost of each sale is directly linked to a single employee of the company. This rule applies to employees equally and to every single sale so that none of the sales is related to an employee. Hence, this type of relationship is classified as one-to-many cardinality.
Many to One Cardinality
Many-to-one cardinality means that the entities of one set are related to one single entity of the other set according to an Entity-Relationship model. As you can tell from the name, this relationship provides the many-to-one mapping. They have two parts inside, which have the following meaning: if there is a need to put only one particular entity on the left side or two or more entities on the right side, other types of cardinality can be used.
In this constraint, several entities in the left set correspond with one entity in the right set. For instance, a Job relationship can link two entities, such as Employee and Sales; more than one employee in a company shares a report with the same manager. However it can be assured globally that every employee will be reporting to only one manager, and no manager can report to more than one manager as it is not allowed in the structure. Consequently, relate follows the many-to-one cardinality.
Many to Many Cardinality
The Many-to-Many Cardinality mapping constraint pertains to a case or scenario within an entity-relationship model where several entities in a set are related to several in another set simultaneously. The name of this constraint is derived from the fact that it supports many-to-many types of relationships; in cases where only the left side or right side of a given scenario is required to contain only one entity, other cardinality types can be used. In this case, it is possible to establish dependency between one or many entities of the left set and one or many entities of the right set.
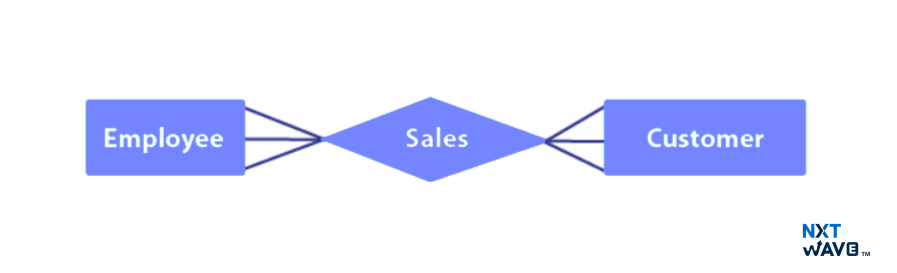
For example, let’s talk about troubles that appear when working with such classes as Employees and Customers connected by the sales relationship. Using the table above, more than one employee can make sales to more than one customer, and customers can also buy from more than one employee. It covers all employees and customers and comprehensively applies to all sales involving any product, irrespective of the amount of money involved. Therefore, it can be concluded that it fits well into many-to-many cardinality types of Entity-Relationship mapping.
Types of key
Keys are like special tools that help keep data organised and accurate. They work as unique labels to identify each piece of information in a table so nothing gets mixed up or repeated. Think of it as a student ID since each student has a different one, which makes it easy to tell them apart.
For example, in a table of employees, an Employee ID can act as a key to identify each person. Without keys, it would be hard to keep track of data or connect information from different tables.
1. Primary key
A Primary Key is a unique identifier for a specific instance of an entity in a table. All entities can have multiple unique keys and the most suitable one is chosen as the primary key. For example, in an EMPLOYEE table, the ID is often selected as the primary key because it uniquely identifies each employee. Other unique attributes, like License_Number or Passport_Number, could also be used as primary keys based on the requirements. The choice of the primary key depends on the needs of the system and the developers.
2. Candidate key
A Candidate Key is an attribute or a group of attributes in a table that can uniquely identify a row of data. It’s like a backup option for a primary key. If one key is chosen as the primary key, the others that could also uniquely identify the rows are called candidate keys.
For example, in an EMPLOYEE table, the ID is first picked as the primary key because it’s the best fit. But other unique attributes, like SSN, Passport_Number, or License_Number, are also considered candidate keys. These keys are just as strong as the primary key but they are second.
3. Super Key
A Super Key is a group of one or more attributes that can uniquely identify a row in a table. It’s like a bigger version of a candidate key because it might include extra information that is not necessary to identify the row.
For example, in an EMPLOYEE table, the EMPLOYEE_ID alone can uniquely identify each employee since two employees can’t have the same ID. But if we combine EMPLOYEE_ID and EMPLOYEE_NAME, that also works as a key, even though the name might not be unique. So, EMPLOYEE_ID and combinations like (EMPLOYEE_ID, EMPLOYEE_NAME) are examples of super keys.
4. Foreign key
A foreign key is a column in a table and it points to the primary key of another table. For example, in a company, every employee works in a specific department. Since employees and departments are separate entities, we can't store department details directly in the employee table. Instead, we can link the two tables using the primary key from one table.
So, we add the primary key, Department_Id, from the DEPARTMENT table into the EMPLOYEE table. Now, the Department_Id in the EMPLOYEE table acts as a foreign key, connecting both tables together.
Generalisation of Entity
Generalisation is a bottom-up approach where two or more lower-level entities combine to form a higher-level entity. But they should share some common attributes. In this process, a higher-level entity can also combine with lower-level entities to create an even higher-level entity. For example, the Faculty and Student entities can be combined to create a higher-level entity called Person.
Specialisation of Entity
Specialisation is a top-down approach, which is the opposite of generalisation. In specialisation, one higher-level entity is broken down into two or more lower-level entities. It's used to identify a specific subset of an entity that shares unique characteristics.
First the superclass is defined first then followed by the subclasses and their related attributes, and then the relationships are added.
For example, in an Employee management system, the EMPLOYEE entity can be specialized into TESTER or DEVELOPER based on the role they play in the company.
Aggregation of Entity
Aggregation is when the relationship between two entities is treated as a single, higher-level entity. In this process, the relationship and its corresponding entities are combined into one entity.
For example, a Center entity and a Course entity can be treated as one entity in a relationship with another entity, like Visitor. In the real world when a visitor visits a coaching center they typically ask about both the Center and the Course, not only about one.
Significance of Mapping Constraints
Mapping constraints are significant because they:
- Clarifies Relationships: mapping constraints determine how entities relate to one another within a model, thus setting a course in data models.
- Enforces Data Integrity: They enforce the adherence to proper relationships between the entities, thus reducing errors in the data.
- Guides Database Design: This is important in mapping databases since it helps define the right way of relating tables appropriately, helping to create order and efficiency.
- Optimizes Query Performance: Mapping can lead to leaner queries since one avoids data duplication and uses a faster method to retrieve information.
- Ensures Flexibility: Constraints can allow relations with different levels of connection, from one-to-one to one-to-many or many-to-many; this brings quite a versatile approach to working with data.
- Supports Business Rules: They also support business rules and conditions, hence aiding in mimicking real life in terms of the database.
- Improves Consistency: This is important since mapping constraints make sure that the database stays consistent even once there is a process of updating the database.
- Facilitates Data Retrieval: Compared to other types of relationships, mapping constraints ensure that data relations are well-defined, which makes it easy to identify your data independently of other entities and link it appropriately.
Conclusion
To conclude, mapping constraints are a very important component of DBMS that sets up and maintains the relationship about the entity-relationship model. It is crucial in data management, the realization of smooth, efficient, and accurate queries, and the achievement of a consistent database. They also play a part in implementing the right data modeling, data validation, and application development. Mapping constraints ensure that the relationship between entities is clearly defined, thus ensuring that databases are accurate, reliable, and more useful since they are integral to any proper data management system.
Boost Your Placement Chances by Learning Industry-Relevant Skills While in College!
Explore ProgramFrequently Asked Questions
1. What is the meaning of mapping constraints in the context of DBMS?
Constraints in DBMS consider the relationships exhibited in an entity-relationship (ER) model. They define the extent of associability between any two entity types, for example, one-to-one, one-to-many or many-to-many.
2. What role do mapping constraints play in database design?
Constraints on mapping help in data integrity and improve the performance of queries and the consistency of a database. It defines the relationship between entities and helps avoid the wrong data relationship.
3. What types of mapping constraints exist in DBMS?
The primary types of mapping constraints are first, one to one, second, one to many, and lastly, many to many. All of them describe how to connect items of one set to items of another set.
4. How do mapping constraints affect query performance?
Properly defined mapping constraints help streamline queries by ensuring efficient relationships between tables. This reduces redundancy and improves the speed of data retrieval. Can mapping constraints be modified after the database is implemented? Yes, different maps may be changed with constraints during the periods of updating and maintaining the database, as well as altering the business rules and application demands. Nevertheless, altering such constraints should be done wisely to support the integrity of the data and keep from violating existing relations.






.avif)